01 / Online Mental Reasoning
Infer mental states from a partial behavior stream
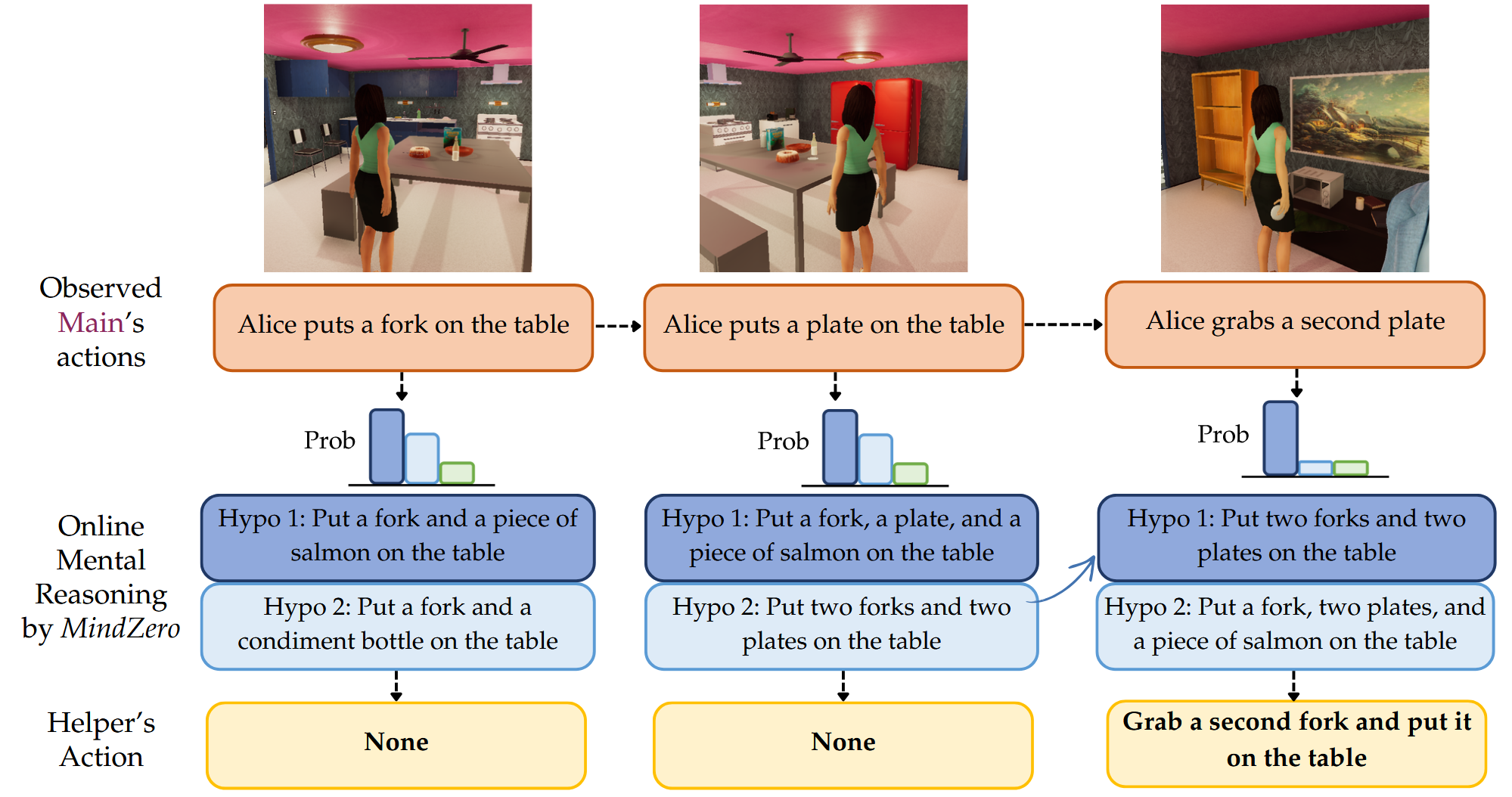
At every time step, the assistant maintains mental-state hypotheses over latent human goals.
- Uncertainty robust uncertainty over multiple hypotheses
- Efficiency fast inference for real-time assistance
- Zero annotations learning with zero ground-truth annotations
03 / Self-Supervised Reinforcement Learning
Amortize model-based ToM into one forward pass
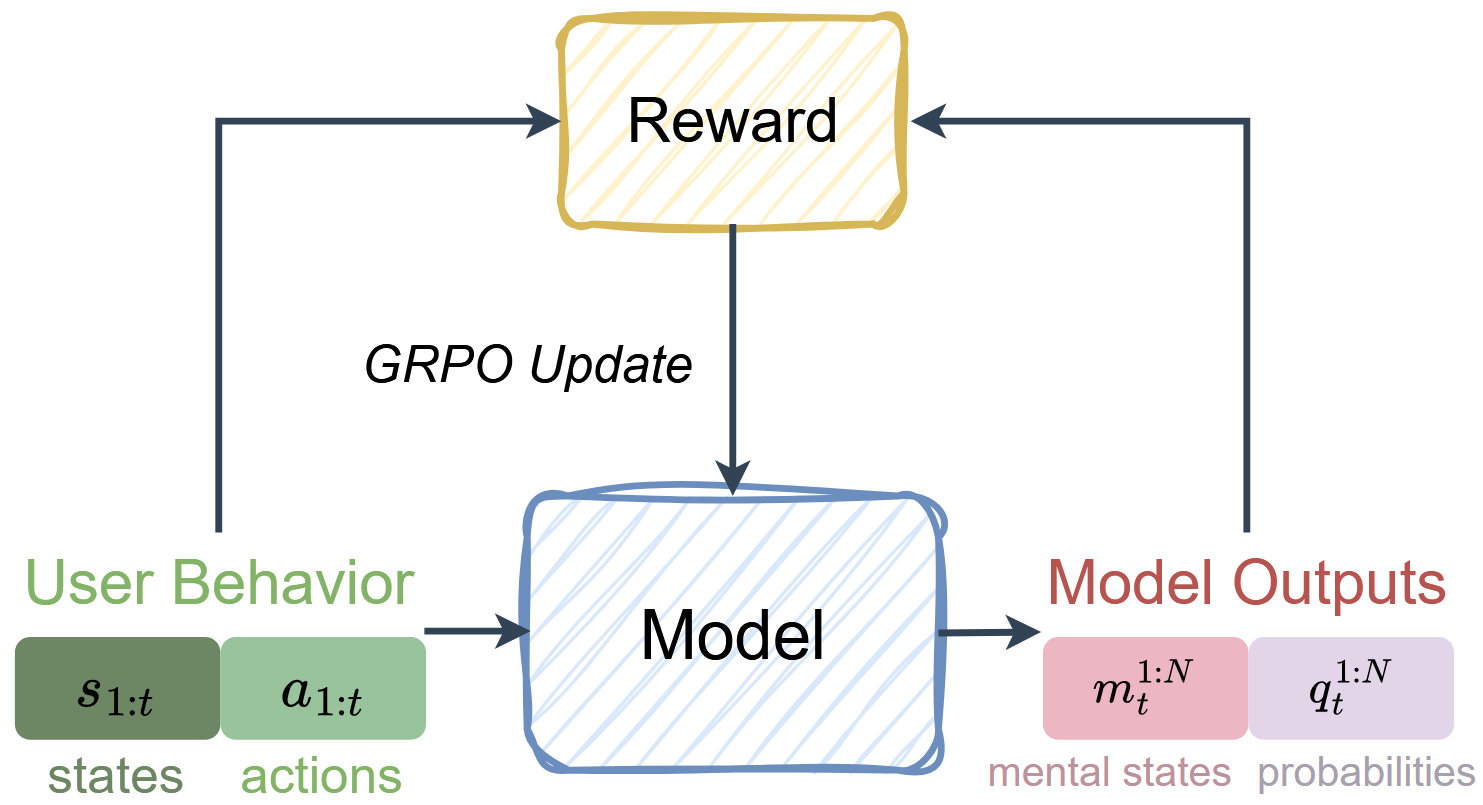
Model-based reasoning can be used as the training signal for amortization.
- Proposal A full particle set of candidate mental states
- Scoring A planner or frozen LLM scorer checks action likelihood
- Optimization Reinforcement learning for non-differentiable scoring
At test time, the model can produce hypotheses in a single pass.
04 / Objective
ELBO as the reward
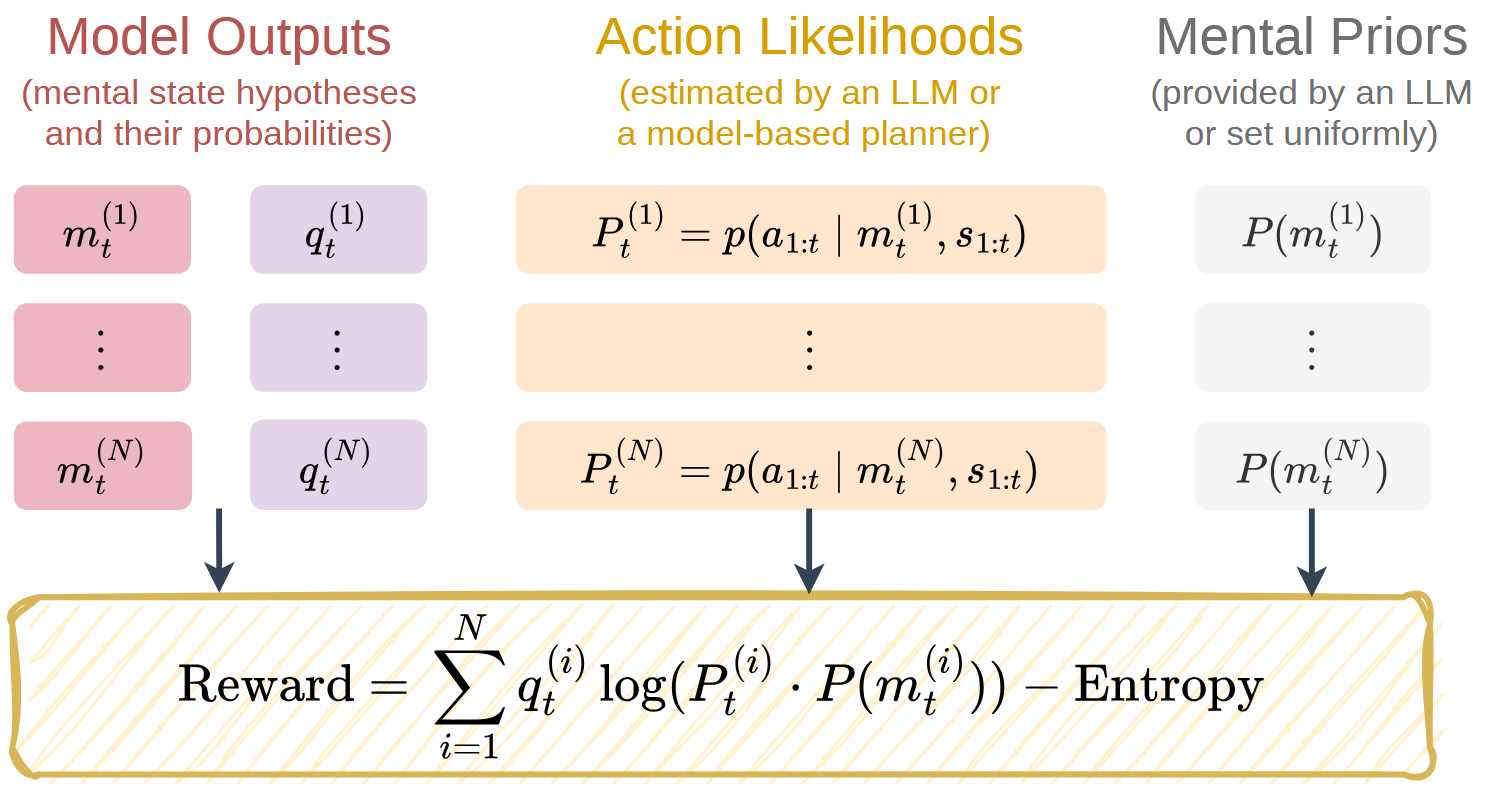
ELBO encourages hypotheses that explain actions and keep uncertainty.
- Likelihood high action likelihood
- Prior prior plausibility
- Entropy discourages early collapse
05 / Setup
Domains and tasks for evaluation
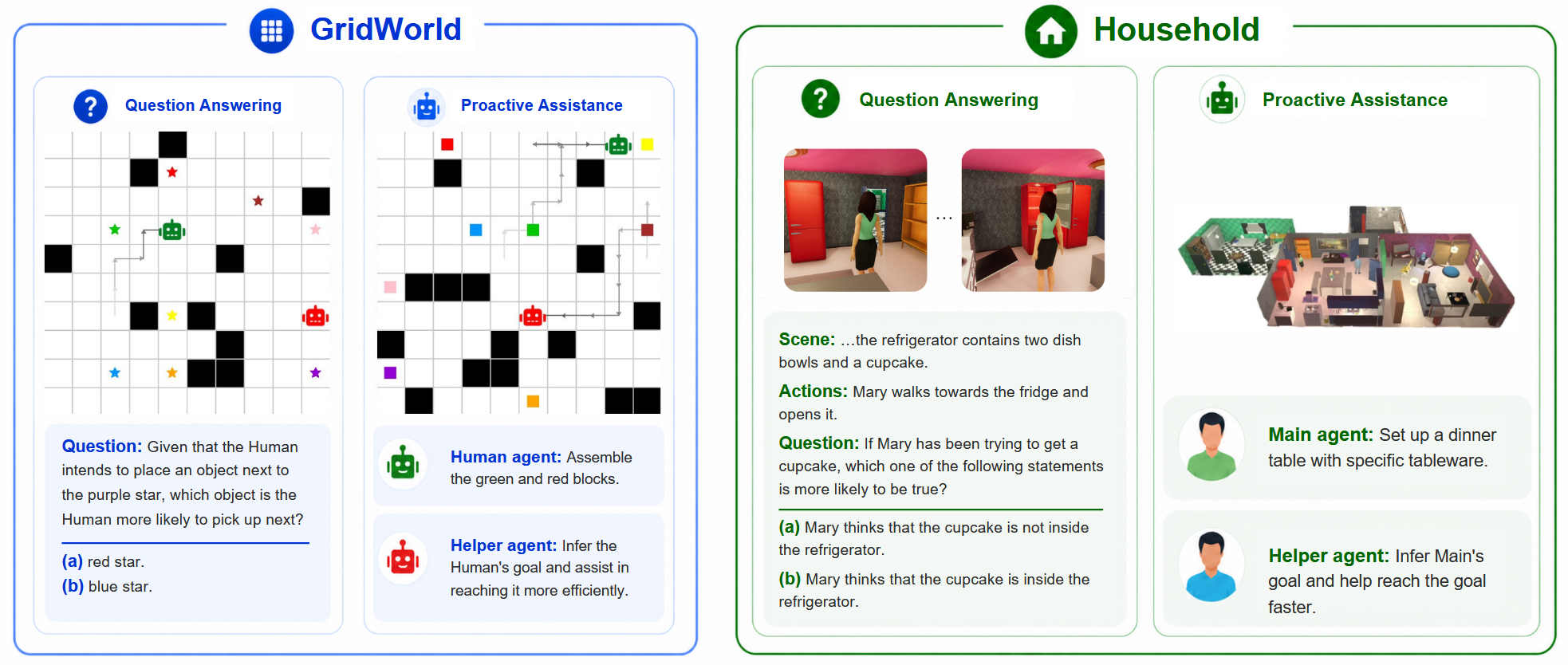
Domains
- GridWorld: visual map input
- Household: text-converted scenarios
Tasks
- Story-based Theory-of-Mind question answering
- Proactive assistance
06 / Question Answering
MindZero improves story-based QA accuracy
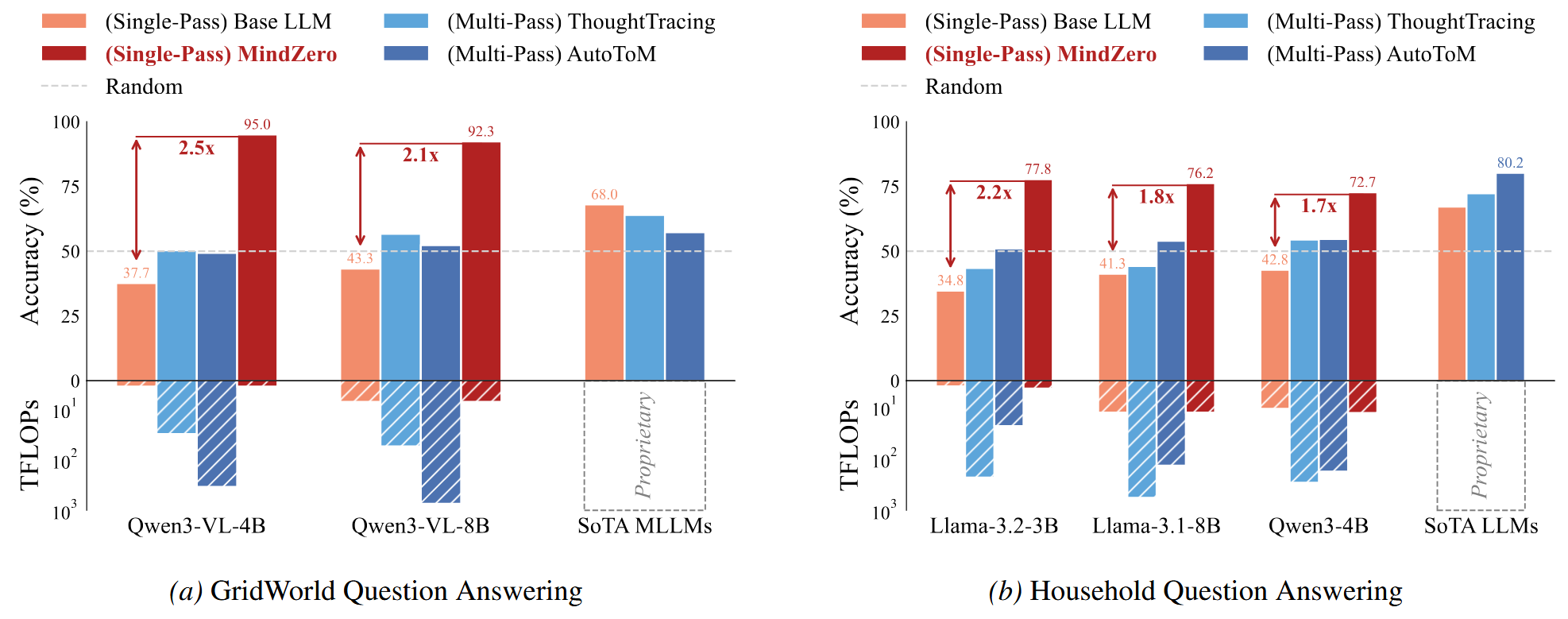
MindZero improves significantly over the pretrained checkpoint and is competitive with strong commercial models using much less computation.
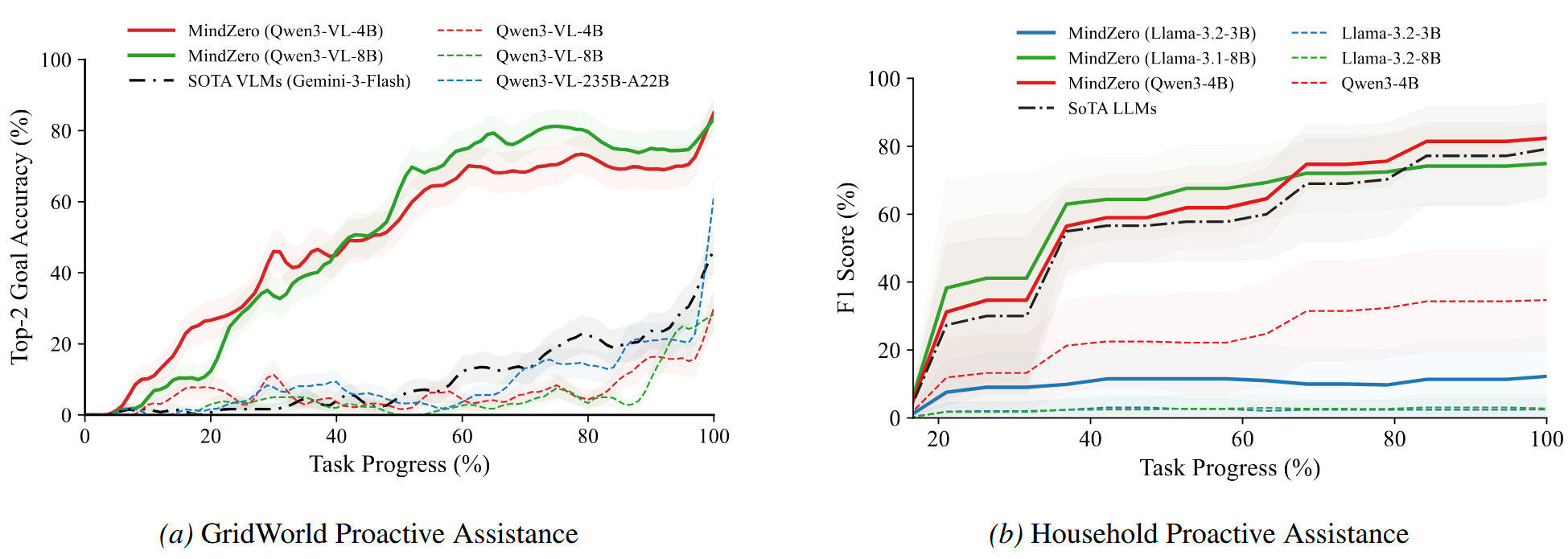
07 / Proactive Assistance
Proactive assistance tests online inference
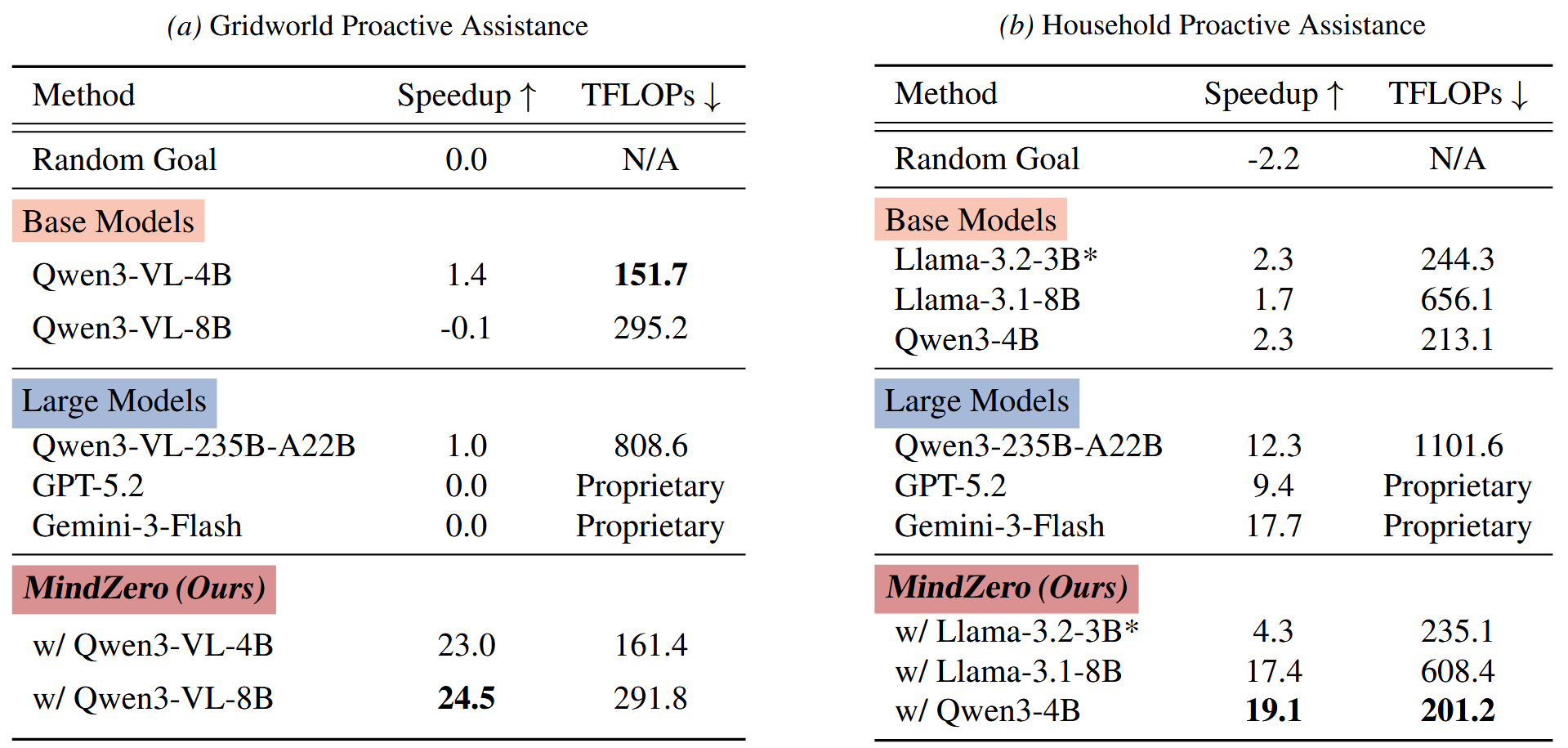
MindZero obtains the best speedup efficiently collaborating with both simulated and real humans.
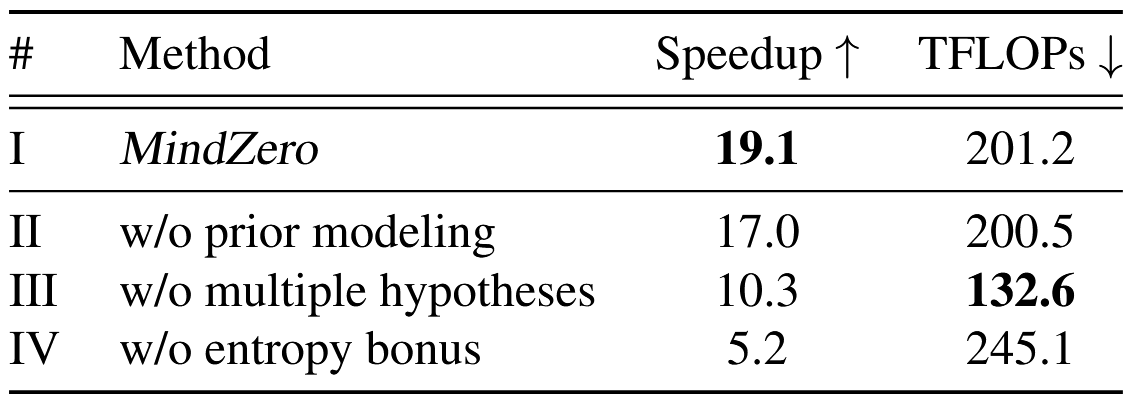
08 / Analysis
Mode seeking does not become mode collapse